# unet_42
**Repository Path**: luoyongcoder/unet_42
## Basic Information
- **Project Name**: unet_42
- **Description**: 基于Unet的医学影像分割系统
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 27
- **Created**: 2022-11-05
- **Last Updated**: 2022-11-05
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# 手把手教你用Unet做医学图像分割
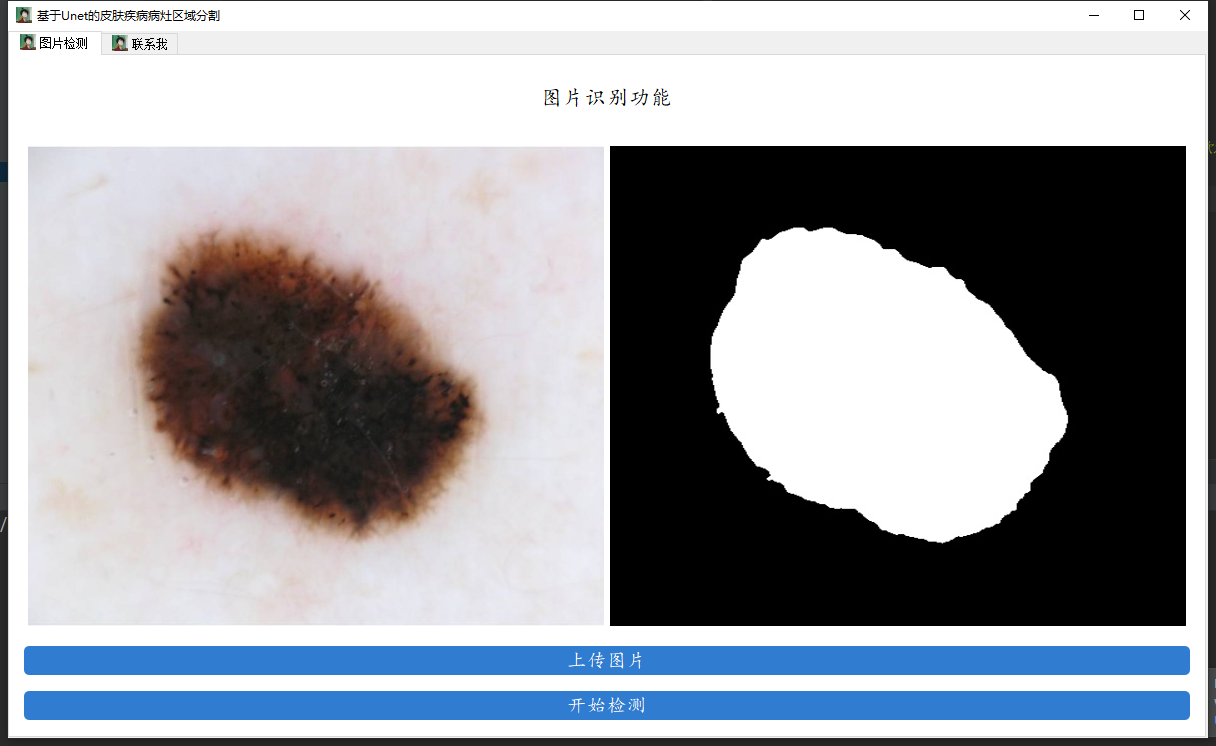
兄弟们好呀,这里是肆十二,这转眼间寒假就要过完了,相信大家的毕设也要准备动手了吧,作为一名大作业区的UP主,也该蹭波热度了,之前关于图像分类和目标检测我们都出了相应的教程,所以这期内容我们搞波新的,我们用Unet来做医学图像分割。我们将会以皮肤病的数据作为示范,训练一个皮肤病分割的模型出来,用户输入图像,模型可以自动分割去皮肤病的区域和正常的区域。废话不多说,先上效果,左侧展示是原始图片,右侧是分割结果。
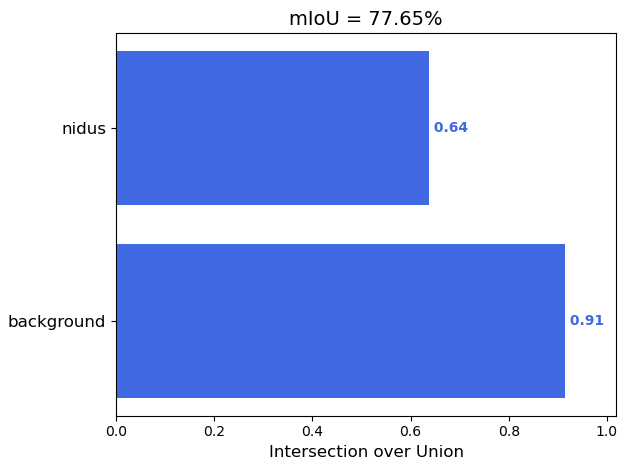
考虑到同学们的论文需要,我这里还做了一些指标图,大家可以放在文章里增加篇幅
需要远程调试的小伙伴直接扫码加我好友(qq: 3045834499)即可,没有三连的小伙伴99元,三连的小伙伴只需49元,你就可以获取环境配置、标注好的数据集、训练好的模型以及远程在线答疑全套服务。

## 算法原理介绍
> 论文地址:https://arxiv.org/pdf/1505.04597.pdf
>
> 算法解析:[U-Net原理分析与代码解读 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/150579454)
Unet 发表于 2015 年,属于 FCN 的一种变体。Unet 的初衷是为了解决生物医学图像方面的问题,由于效果确实很好后来也被广泛的应用在语义分割的各个方向,比如卫星图像分割,工业瑕疵检测等。
Unet 跟 FCN 都是 Encoder-Decoder 结构,结构简单但很有效。Encoder 负责特征提取,你可以将自己熟悉的各种特征提取网络放在这个位置。由于在医学方面,样本收集较为困难,作者为了解决这个问题,应用了图像增强的方法,在数据集有限的情况下获得了不错的精度。
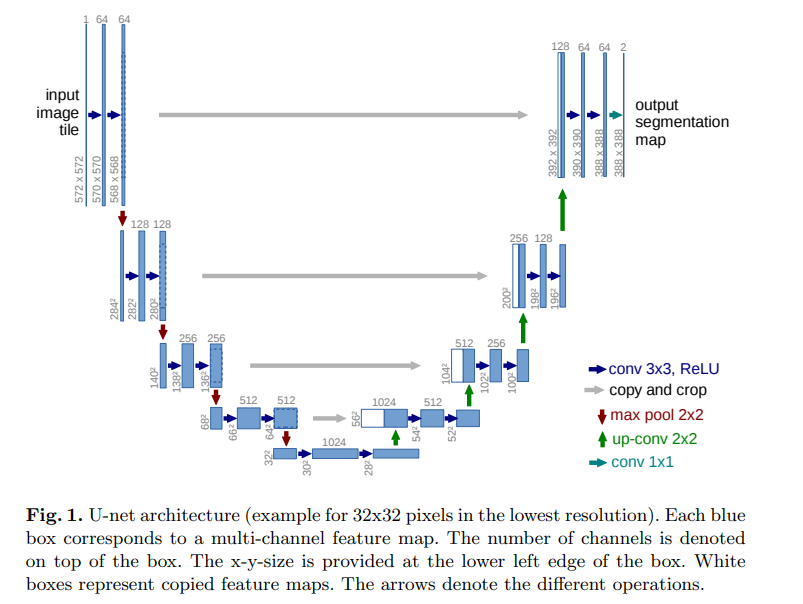
如上图,Unet 网络结构是对称的,形似英文字母 U 所以被称为 Unet,在一些类别较少的数据集上,一般使用unet来做语义分割,尤其是在一些二分类的任务上,不仅仅模型比较小,而且在精度上也比较高。
更加详细的原理介绍大家可以参考原文以及大佬们在知乎和csdn上的解答,我在这里就不多做赘述了。
## 下载代码
老规矩,代码放在码云上,地址是:
大家下载之后放在本地就行
**注:请大家使用chrome浏览器或者windows本地自带的edge浏览器下载,否则可能会出现压缩包损坏的bug,而且解压强烈安利大家使用bandzip。**
## 配置环境
不熟悉pycharm的anaconda的小伙伴请先看这篇csdn博客,了解pycharm和anaconda的基本操作
[如何在pycharm中配置anaconda的虚拟环境_dejahu的博客-CSDN博客_如何在pycharm中配置anaconda](https://blog.csdn.net/ECHOSON/article/details/117220445)
anaconda安装完成之后请切换到国内的源来提高下载速度 ,命令如下:
```bash
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
```
首先创建python3.8的虚拟环境,请在命令行中执行下列操作:
```bash
conda create -n unet python==3.8.5
conda activate unet
```
### pytorch安装(gpu版本和cpu版本的安装)
实际测试情况是unet在CPU和GPU的情况下均可使用,不过在CPU的条件下训练那个速度会令人发指,所以有条件的小伙伴一定要安装GPU版本的Pytorch,没有条件的小伙伴最好是租服务器来使用。
GPU版本安装的具体步骤可以参考这篇文章:[2021年Windows下安装GPU版本的Tensorflow和Pytorch_dejahu的博客-CSDN博客](https://blog.csdn.net/ECHOSON/article/details/118420968)
需要注意以下几点:
* 安装之前一定要先更新你的显卡驱动,去官网下载对应型号的驱动安装
* 30系显卡只能使用cuda11的版本
* 一定要创建虚拟环境,这样的话各个深度学习框架之间不发生冲突
我这里创建的是python3.8的环境,安装的Pytorch的版本是1.8.0,命令如下:
```cmd
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
```
安装完毕之后,我们来测试一下GPU是否
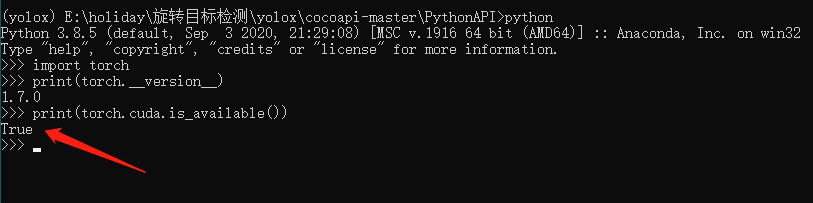
### 安装unet程序所需的其他包
程序其他所需要的包我写在了`requirements.txt`文件中,大家只需要在项目目录下打开cmd,然后执行下列命令安装即可,**安装之前请确保你已经激活了虚拟环境**
```bash
pip install -r requirements.txt
```
到这里我们的环境基本已经配置完成了,你已经成功了一大半了,下面只需要按照教程完成剩下的步骤即可。
## 数据处理
数据处理部分,医学影像这块我们一般使用公开的数据集,如果没有合适的数据集大家也可以选择自己进行标注,分割相对于检测而言标注起来比较麻烦,所以能找到公开的数据集最好使用公开的数据集,这里也放一些我收集和处理好的数据集,大家有需要的可以自取。
以下面的皮肤病数据集为例,其中左侧是原始图片,右侧是标注之后的标签,因为标签有两种像素值,背景为0,皮肤病区域为1,所以我们肉眼上看到的标签图片是全黑,但是实际上这些标签文件中的值是不一样的。
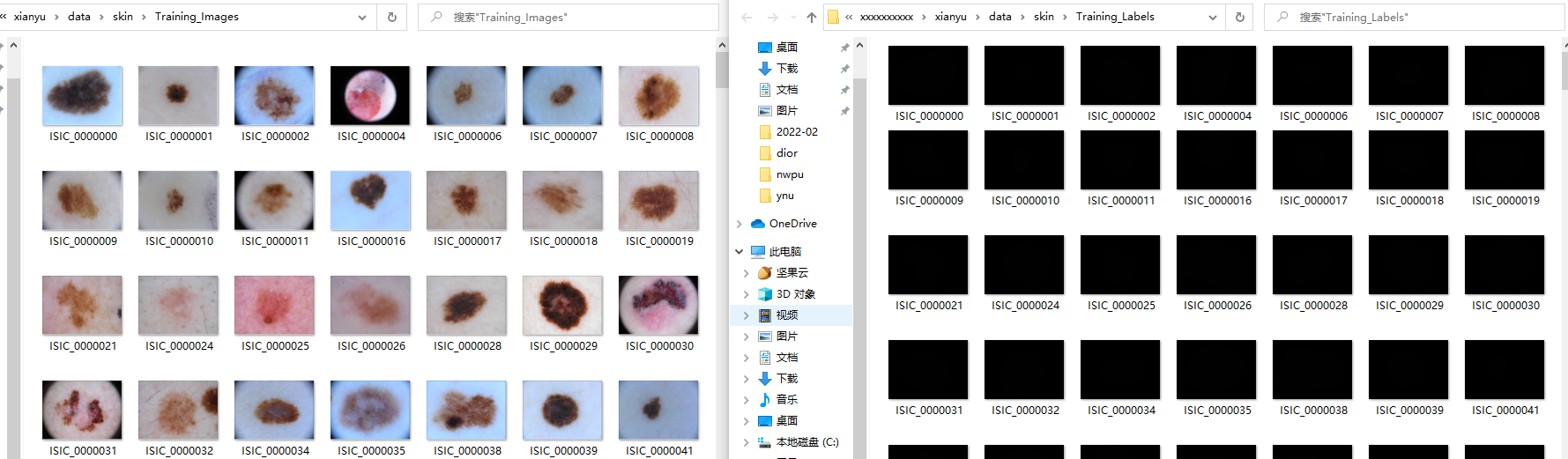
记住这里数据集的位置,后面在训练和测试的时候在代码中替换为自己本地的数据集位置。
**注:下面的内容是关于数据集的标注,如果大家已经找到合适的数据集,请自行跳过这部分的内容**
* 1.LabelMe的安装
用户在采集完用于训练、评估和预测的图片之后,需使用数据标注工具[LabelMe](https://github.com/wkentaro/labelme)完成数据标注。LabelMe支持在Windows/macOS/Linux三个系统上使用,且三个系统下的标注格式是一样。
安装的过程非常简单,大家只需要在激活虚拟环境的前提下,执行下列之类即可
```
pip install labelme
```
安装完成之后,直接在命令行中输入`labelme`即可启动
* 2.LabelMe的使用
打开终端输入`labelme`会出现LableMe的交互界面,可以先预览`LabelMe`给出的已标注好的图片,再开始标注自定义数据集。
* 预览已标注图片
终端输入`labelme`会出现LableMe的交互界面,点击`OpenDir`打开`/examples/semantic_segmentation/data_annotated`,其中``为克隆下来的`labelme`的路径,打开后示意的是语义分割的真值标注。
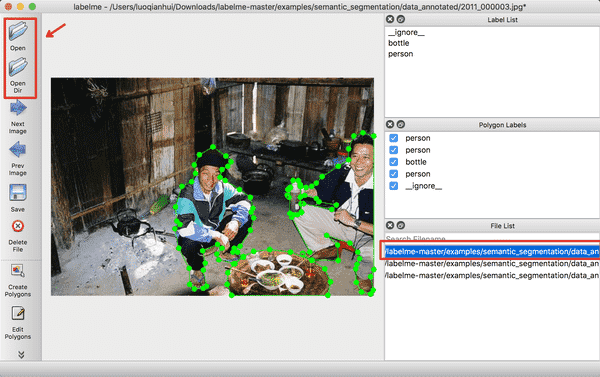
* 开始标注
请按照下述步骤标注数据集:
(1) 点击`OpenDir`打开待标注图片所在目录,点击`Create Polygons`,沿着目标的边缘画多边形,完成后输入目标的类别。在标注过程中,如果某个点画错了,可以按撤销快捷键可撤销该点。Mac下的撤销快捷键为`command+Z`。
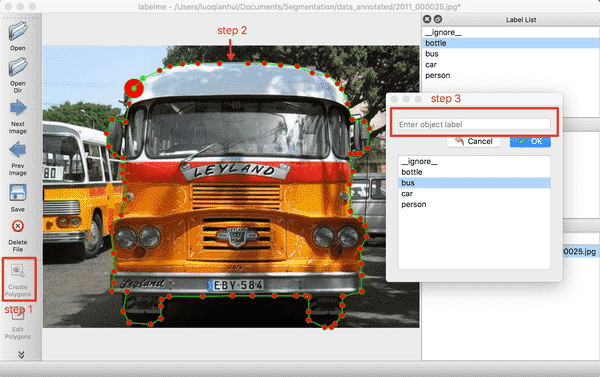
(2) 右击选择`Edit Polygons`可以整体移动多边形的位置,也可以移动某个点的位置;右击选择`Edit Label`可以修改每个目标的类别。请根据自己的需要执行这一步骤,若不需要修改,可跳过。
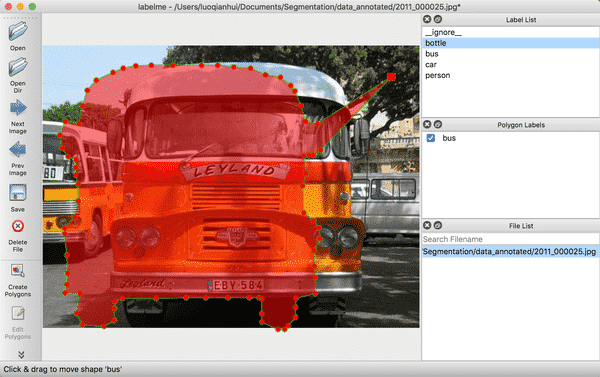
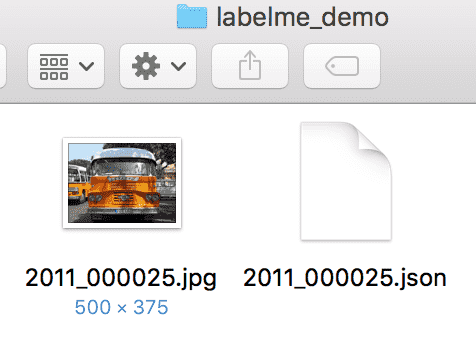
(3) 图片中所有目标的标注都完成后,点击`Save`保存json文件,**请将json文件和图片放在同一个文件夹里**,点击`Next Image`标注下一张图片。
LableMe产出的真值文件可参考我们给出的[文件夹](https://github.com/PaddlePaddle/PaddleSeg/blob/release/v0.8.0/docs/annotation/labelme_demo)。
**Note:**
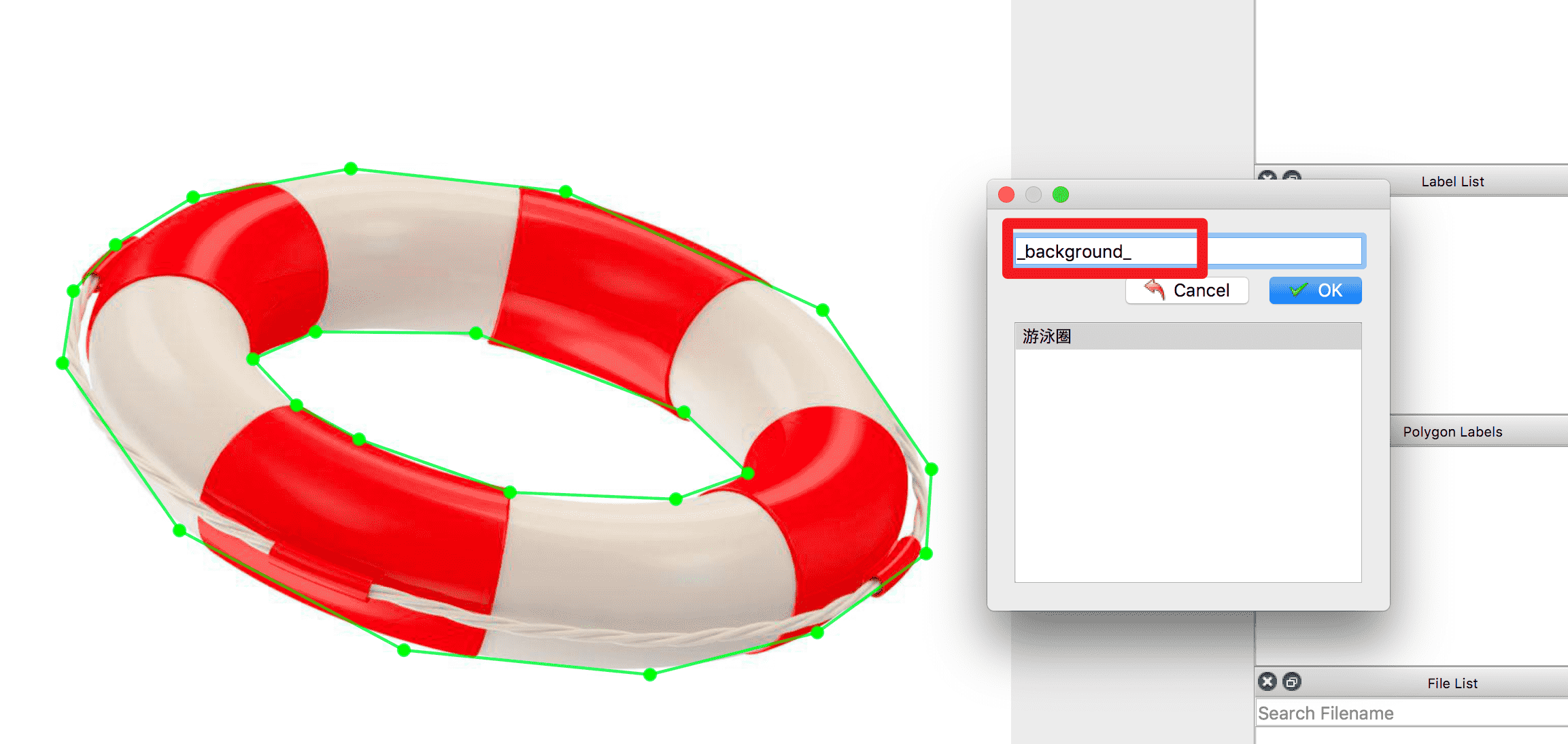
对于中间有空洞的目标的标注方法:在标注完目标轮廓后,再沿空洞区域边缘画多边形,并将其指定为其他类别,如果是背景则指定为`_background_`。如下:
* 3.数据格式转换
最后用我们提供的数据转换脚本将上述标注工具产出的数据格式转换为模型训练时所需的数据格式。
* 经过数据格式转换后的数据集目录结构如下:
```
my_dataset # 根目录
|-- annotations # 数据集真值
| |-- xxx.png # 像素级别的真值信息
| |...
|-- class_names.txt # 数据集的类别名称
|-- xxx.jpg(png or other) # 数据集原图
|-- ...
|-- xxx.json # 标注json文件
|-- ...
```

* 4.运行以下代码,将标注后的数据转换成满足以上格式的数据集:
```bash
python labelme2seg.py
```
其中,``为图片以及LabelMe产出的json文件所在文件夹的目录,同时也是转换后的标注集所在文件夹的目录。
我们已内置了一个标注的示例,可运行以下代码进行体验:
```bash
python labelme2seg.py docs/annotation/labelme_demo/
```
转换得到的数据集可参考我们给出的[文件夹](https://github.com/PaddlePaddle/PaddleSeg/blob/release/v0.8.0/docs/annotation/labelme_demo)。其中,文件`class_names.txt`是数据集中所有标注类别的名称,包含背景类;文件夹`annotations`保存的是各图片的像素级别的真值信息,背景类`_background_`对应为0,其它目标类别从1开始递增,至多为255。
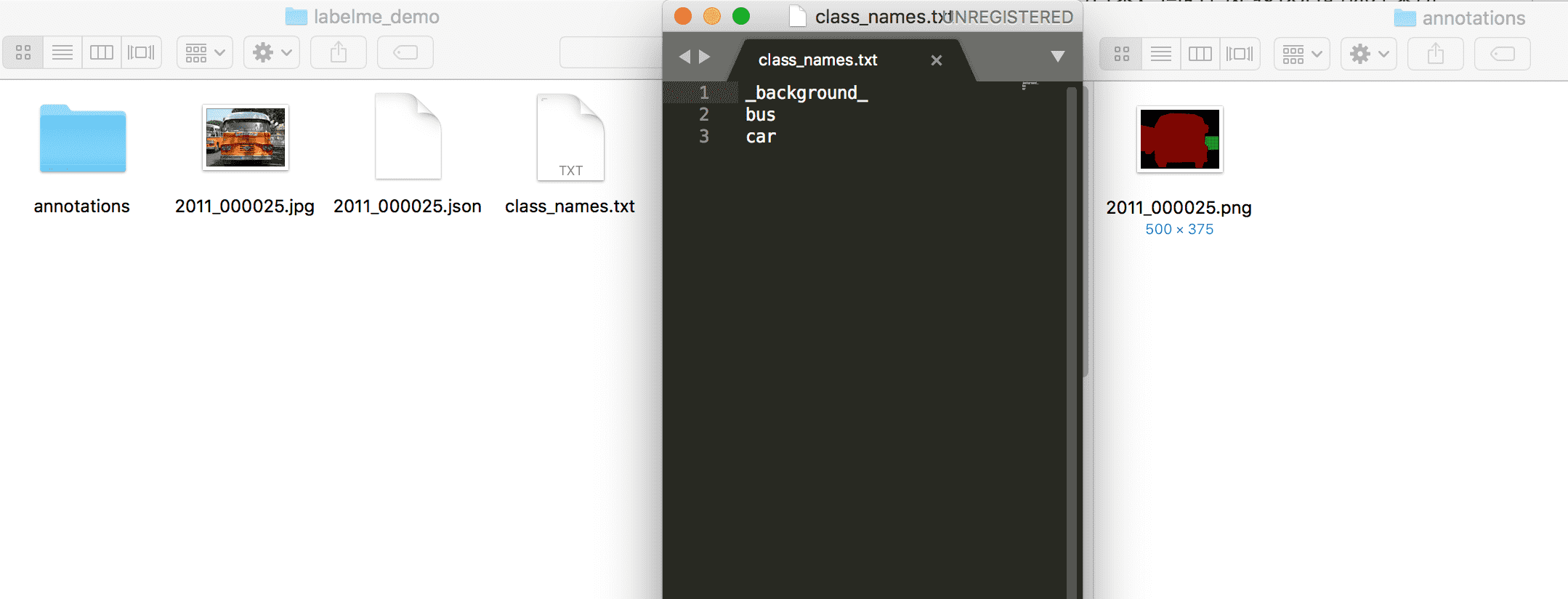
## 模型训练
现在来到模型训练的环境,首先请大家把自己的图片和标签按照下面的文件夹命名放在对应的位置。
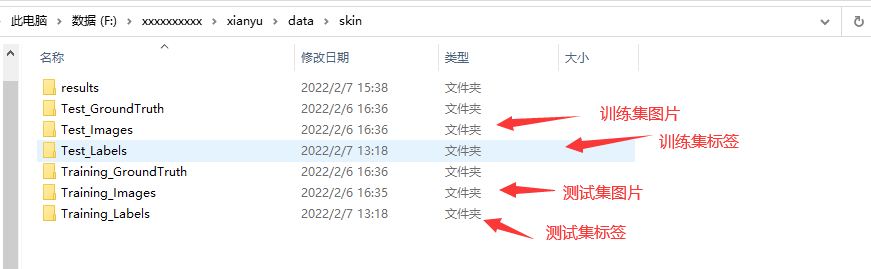
比如我这里的数据集位置在`F:/xxxxxxxxxx/xianyu/data/skin`
然后大家找到项目的train目录,修改数据集的位置即可
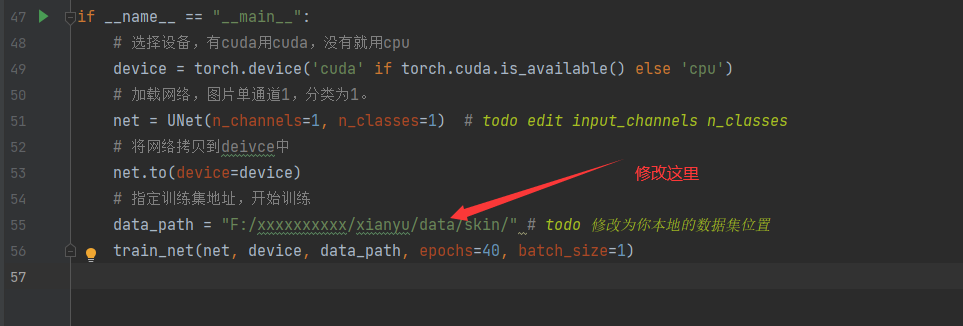
修改之后,直接右键`run`运行`train.py`即可,训练过程中将会有个进度条来显示你训练的速度,如果是GPU的话速度会很快

模型将会保存在本地目录下:
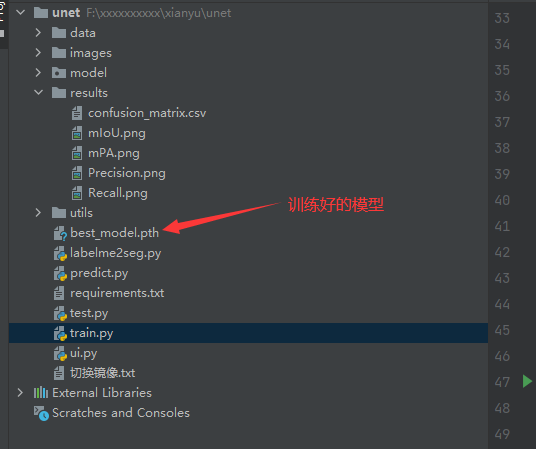
## 模型验证
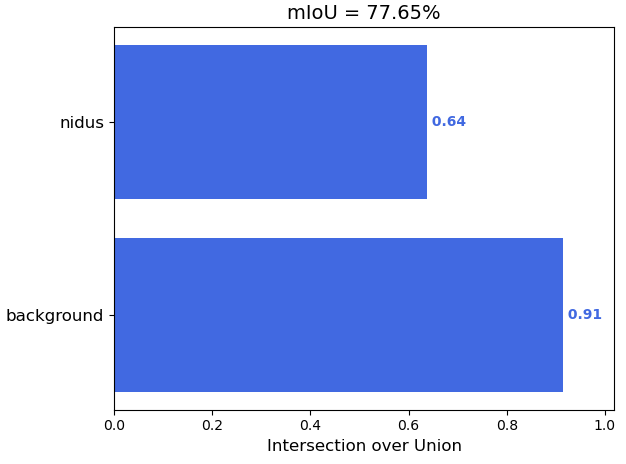
模型训练结束之后,我们可以使用一些指标来测试模型的性能,语义分割常用的测试指标是miou,定义如下:

这部分代码在`test.py`文件中,和刚才的`train.py`一样,大家只需要更改模型和数据集的位置即可
首先需要大家在22行修改需要测试的图片路径,测试结果保存的路径,和测试标签的路径

然后再代码的第59行修改为对应的模型名称即可。

修改完成之后直接右键run开始运行,运行的结果将会保存在项目目录的results文件夹下:
大家可以在论文中用自己的语言阐述这三个指标,然后放对应的图上去,这样你的毕设就显得有血有肉了。
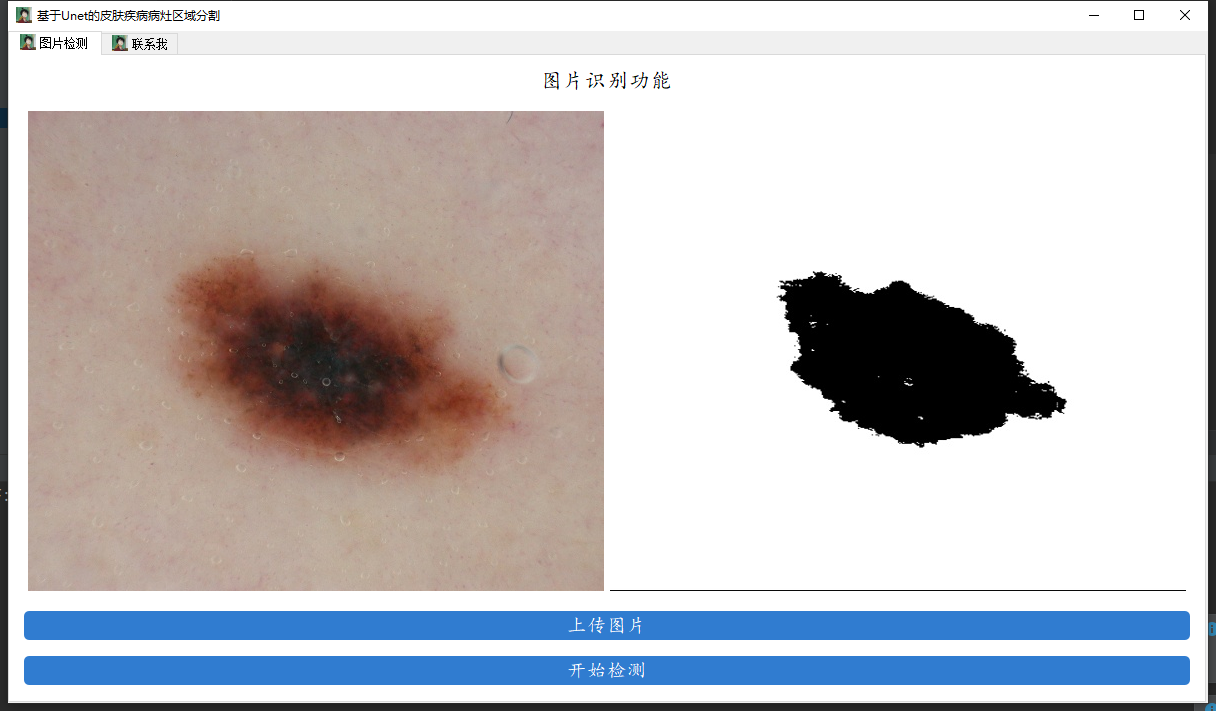
## 图形化界面
最后就是我们这个语义分割的系统了,系统本身很复杂,但是只是毕设,所以这里的系统简单理解就是用Pyqt5给我们的代码加个壳子这样,系统的代码在ui.py,大家只需要在代码的第46行修改为自己的模型文件即可。

运行的结果如下:
## 找到我
需要远程的调试的小伙伴直接扫码加我好友(qq: 3045834499)即可,没有三连的小伙伴99元,三连的小伙伴只需49元,你就可以获取环境配置、标注好的数据集、训练好的模型以及远程在线答疑全套服务。
你可以通过这些方式来寻找我。
B站:[肆十二-](https://space.bilibili.com/161240964)
CSDN:[肆十二](https://blog.csdn.net/ECHOSON)
知乎:[肆十二 ](https://www.zhihu.com/people/song-chen-ming-28)
微博:[肆十二-](https://weibo.com/u/5999979327)
现在关注以后就是老朋友喽!