# metaformer
**Repository Path**: AIHao4585/metaformer
## Basic Information
- **Project Name**: metaformer
- **Description**: No description available
- **Primary Language**: Unknown
- **License**: Apache-2.0
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-10-09
- **Last Updated**: 2025-10-09
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# [MetaFormer Baselines for Vision](https://arxiv.org/abs/2210.13452) (TPAMI 2024)


This is a PyTorch implementation of several MetaFormer baslines including **IdentityFormer**, **RandFormer**, **ConvFormer** and **CAFormer** proposed by our paper "[MetaFormer Baselines for Vision](https://arxiv.org/abs/2210.13452)".

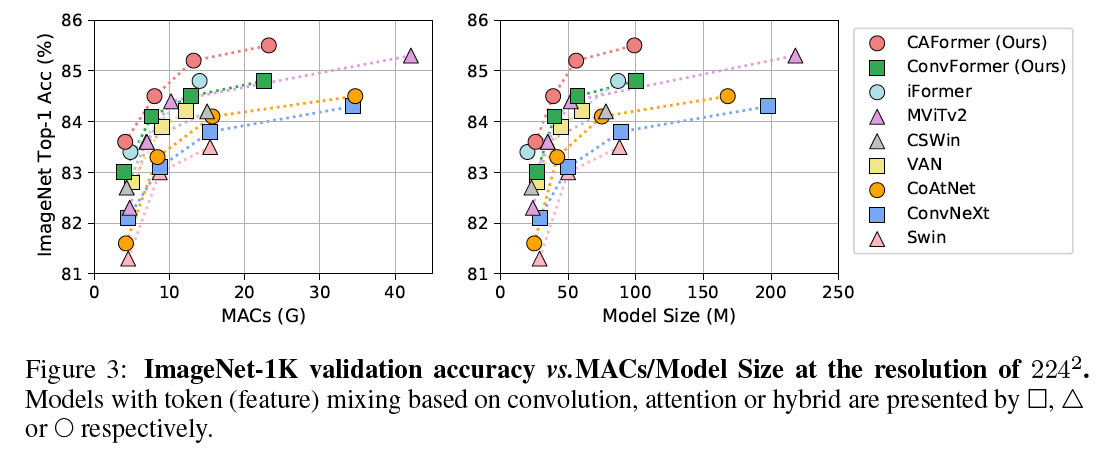
Figure 1: **Performance of MetaFormer baselines and other state-of-the-art models on ImageNet-1K at 224x224 resolution.** The architectures of our proposed models are shown in Figure 2. (a) IdentityFormer/RandFormer achieve over 80%/81% accuracy, indicating MetaFormer has solid lower bound of performance and works well on arbitrary token mixers. The accuracy of well-trained ResNet-50 is from "ResNet strikes back". (b) Without novel token mixers, pure CNN-based ConvFormer outperforms ConvNeXt, while CAFormer sets a new record of 85.5% accuracy on ImageNet-1K at 224x224 resolution under normal supervised training without external data or distillation.

Figure 2: **(a-d) Overall frameworks of IdentityFormer, RandFormer, ConvFormer and CAFormer.** Similar to ResNet, the models adopt hierarchical architecture of 4 stages, and stage $i$ has $L_i$ blocks with feature dimension $D_i$. Each downsampling module is implemented by a layer of convolution. The first downsampling has kernel size of 7 and stride of 4, while the last three ones have kernel size of 3 and stride of 2. **(e-h) Architectures of IdentityFormer, RandFormer, ConvFormer and Transformer blocks**, which have token mixer of identity mapping, global random mixing, separable depthwise convolutions, or vanilla self-attention, respectively.
### News
Models of MetaFormer baselines are now integrated in [timm](https://github.com/huggingface/pytorch-image-models) by [Fredo Guan](https://github.com/fffffgggg54) and [Ross Wightman](https://github.com/rwightman). Many thanks!
## Requirements
torch>=1.7.0; torchvision>=0.8.0; pyyaml; [timm](https://github.com/rwightman/pytorch-image-models) (`pip install timm==0.6.11`)
Data preparation: ImageNet with the following folder structure, you can extract ImageNet by this [script](https://gist.github.com/BIGBALLON/8a71d225eff18d88e469e6ea9b39cef4).
```
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
```
## MetaFormer baselines
### Models with common token mixers trained on ImageNet-1K
| Model | Resolution | Params | MACs | Top1 Acc | Download |
| :--- | :---: | :---: | :---: | :---: | :---: |
| caformer_s18 | 224 | 26M | 4.1G | 83.6 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s18.pth) |
| caformer_s18_384 | 384 | 26M | 13.4G | 85.0 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s18_384.pth) |
| caformer_s36 | 224 | 39M | 8.0G | 84.5 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s36.pth) |
| caformer_s36_384 | 384 | 39M | 26.0G | 85.7 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s36_384.pth) |
| caformer_m36 | 224 | 56M | 13.2G | 85.2 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_m36.pth) |
| caformer_m36_384 | 384 | 56M | 42.0G | 86.2 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_m36_384.pth) |
| caformer_b36 | 224 | 99M | 23.2G | **85.5**\* | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_b36.pth) |
| caformer_b36_384 | 384 | 99M | 72.2G | **86.4** | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_b36_384.pth) |
| convformer_s18 | 224 | 27M | 3.9G | 83.0 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s18.pth) |
| convformer_s18_384 | 384 | 27M | 11.6G | 84.4 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s18_384.pth) |
| convformer_s36 | 224 | 40M | 7.6G | 84.1 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s36.pth) |
| convformer_s36_384 | 384 | 40M | 22.4G | 85.4 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s36_384.pth) |
| convformer_m36 | 224 | 57M | 12.8G | 84.5 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_m36.pth) |
| convformer_m36_384 | 384 | 57M | 37.7G | 85.6 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_m36_384.pth) |
| convformer_b36 | 224 | 100M | 22.6G | 84.8 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_b36.pth) |
| convformer_b36_384 | 384 | 100M | 66.5G | 85.7 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_b36_384.pth) |
:astonished: :astonished: \* To the best of our knowledge, the model sets a new record on ImageNet-1K with the accuracy of 85.5% at 224x224 resolution under normal supervised setting (without external data or distillation).
### Models with common token mixers pretrained on ImageNet-21K and finetuned on ImgeNet-1K
| Model | Resolution | Params | MACs | Top1 Acc | Download |
| :--- | :---: | :---: | :---: | :---: | :---: |
| caformer_s18_in21ft1k | 224 | 26M | 4.1G | 84.1 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s18_in21ft1k.pth) |
| caformer_s18_384_in21ft1k | 384 | 26M | 13.4G | 85.4 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s18_384_in21ft1k.pth) |
| caformer_s36_in21ft1k | 224 | 39M | 8.0G | 85.8 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s36_in21ft1k.pth) |
| caformer_s36_384_in21ft1k | 384 | 39M | 26.0G | 86.9 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s36_384_in21ft1k.pth) |
| caformer_m36_in21ft1k | 224 | 56M | 13.2G | 86.6 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_m36_in21ft1k.pth) |
| caformer_m36_384_in21ft1k | 384 | 56M | 42.0G | 87.5 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_m36_384_in21ft1k.pth) |
| caformer_b36_in21ft1k | 224 | 99M | 23.2G | 87.4 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_b36_in21ft1k.pth) |
| caformer_b36_384_in21ft1k | 384 | 99M | 72.2G | 88.1 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_b36_384_in21ft1k.pth) |
| convformer_s18_in21ft1k | 224 | 27M | 3.9G | 83.7 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s18_in21ft1k.pth) |
| convformer_s18_384_in21ft1k | 384 | 27M | 11.6G | 85.0 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s18_384_in21ft1k.pth) |
| convformer_s36_in21ft1k | 224 | 40M | 7.6G | 85.4 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s36_in21ft1k.pth) |
| convformer_s36_384_in21ft1k | 384 | 40M | 22.4G | 86.4 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s36_384_in21ft1k.pth) |
| convformer_m36_in21ft1k | 224 | 57M | 12.8G | 86.1 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_m36_in21ft1k.pth) |
| convformer_m36_384_in21ft1k | 384 | 57M | 37.7G | 86.9 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_m36_384_in21ft1k.pth) |
| convformer_b36_in21ft1k | 224 | 100M | 22.6G | 87.0 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_b36_in21ft1k.pth) |
| convformer_b36_384_in21kft1k | 384 | 100M | 66.5G | 87.6 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_b36_384_in21ft1k.pth) |
### Models with common token mixers pretrained on ImageNet-21K
| Model | Resolution | Download |
| :--- | :---: | :---: |
| caformer_s18_in21k | 224 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s18_in21k.pth) |
| caformer_s36_in21k | 224 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_s36_in21k.pth) |
| caformer_m36_in21k | 224 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_m36_in21k.pth) |
| caformer_b36_in21k | 224 | [here](https://huggingface.co/sail/dl/resolve/main/caformer/caformer_b36_in21k.pth) |
| convformer_s18_in21k | 224 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s18_in21k.pth) |
| convformer_s36_in21k | 224 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_s36_in21k.pth) |
| convformer_m36_in21k | 224 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_m36_in21k.pth) |
| convformer_b36_in21k | 224 | [here](https://huggingface.co/sail/dl/resolve/main/convformer/convformer_b36_in21k.pth) |
### Models with basic token mixers trained on ImageNet-1K
| Model | Resolution | Params | MACs | Top1 Acc | Download |
| :--- | :---: | :---: | :---: | :---: | :---: |
| identityformer_s12 | 224 | 11.9M | 1.8G | 74.6 | [here](https://huggingface.co/sail/dl/resolve/main/identityformer/identityformer_s12.pth) |
| identityformer_s24 | 224 | 21.3M | 3.4G | 78.2 | [here](https://huggingface.co/sail/dl/resolve/main/identityformer/identityformer_s24.pth) |
| identityformer_s36 | 224 | 30.8M | 5.0G | 79.3 | [here](https://huggingface.co/sail/dl/resolve/main/identityformer/identityformer_s36.pth) |
| identityformer_m36 | 224 | 56.1M | 8.8G | 80.0 | [here](https://huggingface.co/sail/dl/resolve/main/identityformer/identityformer_m36.pth) |
| identityformer_m48 | 224 | 73.3M | 11.5G | 80.4 | [here](https://huggingface.co/sail/dl/resolve/main/identityformer/identityformer_m48.pth) |
| randformer_s12 | 224 | 11.9 + 0.2M | 1.9G | 76.6 | [here](https://huggingface.co/sail/dl/resolve/main/randformer/randformer_s12.pth) |
| randformer_s24 | 224 | 21.3 + 0.5M | 3.5G | 78.2 | [here](https://huggingface.co/sail/dl/resolve/main/randformer/randformer_s24.pth) |
| randformer_s36 | 224 | 30.8 + 0.7M | 5.2G | 79.5 | [here](https://huggingface.co/sail/dl/resolve/main/randformer/randformer_s36.pth) |
| randformer_m36 | 224 | 56.1 + 0.7M | 9.0G | 81.2 | [here](https://huggingface.co/sail/dl/resolve/main/randformer/randformer_m36.pth) |
| randformer_m48 | 224 | 73.3 + 0.9M | 11.9G | 81.4 | [here](https://huggingface.co/sail/dl/resolve/main/randformer/randformer_m48.pth) |
| poolformerv2_s12 | 224 | 11.9M | 1.8G | 78.0 | [here](https://huggingface.co/sail/dl/resolve/main/poolformerv2/poolformerv2_s12.pth) |
| poolformerv2_s24 | 224 | 21.3M | 3.4G | 80.7 | [here](https://huggingface.co/sail/dl/resolve/main/poolformerv2/poolformerv2_s24.pth) |
| poolformerv2_s36 | 224 | 30.8M | 5.0G | 81.6 | [here](https://huggingface.co/sail/dl/resolve/main/poolformerv2/poolformerv2_s36.pth) |
| poolformerv2_m36 | 224 | 56.1M | 8.8G | 82.2 | [here](https://huggingface.co/sail/dl/resolve/main/poolformerv2/poolformerv2_m36.pth) |
| poolformerv2_m48 | 224 | 73.3M | 11.5G | 82.6 | [here](https://huggingface.co/sail/dl/resolve/main/poolformerv2/poolformerv2_m48.pth) |
The underlined numbers mean the numbers of parameters that are frozen after random initialization.
The checkpoints can also be found in [Baidu Disk](https://pan.baidu.com/s/1qJ-MHbuQyEdN7a6DJY9RFg?pwd=meta).
#### Usage
We also provide a Colab notebook which run the steps to perform inference with MetaFormer baselines: [](https://colab.research.google.com/drive/1raon_oZRnUBXb9ZYcMY3Au_r-3l4eP1I?usp=sharing)
## Validation
To evaluate our CAFormer-S18 models, run:
```bash
MODEL=caformer_s18
python3 validate.py /path/to/imagenet --model $MODEL -b 128 \
--checkpoint /path/to/checkpoint
```
## Train
We use batch size of 4096 by default and we show how to train models with 8 GPUs. For multi-node training, adjust `--grad-accum-steps` according to your situations.
```bash
DATA_PATH=/path/to/imagenet
CODE_PATH=/path/to/code/metaformer # modify code path here
ALL_BATCH_SIZE=4096
NUM_GPU=8
GRAD_ACCUM_STEPS=4 # Adjust according to your GPU numbers and memory size.
let BATCH_SIZE=ALL_BATCH_SIZE/NUM_GPU/GRAD_ACCUM_STEPS
cd $CODE_PATH && sh distributed_train.sh $NUM_GPU $DATA_PATH \
--model convformer_s18 --opt adamw --lr 4e-3 --warmup-epochs 20 \
-b $BATCH_SIZE --grad-accum-steps $GRAD_ACCUM_STEPS \
--drop-path 0.2 --head-dropout 0.0
```
Training (fine-tuning) scripts of other models are shown in [scripts](/scripts/).
## Acknowledgment
Weihao Yu would like to thank TRC program and GCP research credits for the support of partial computational resources. Our implementation is based on the wonderful [pytorch-image-models](https://github.com/rwightman/pytorch-image-models) codebase.
## Bibtex
```
@article{yu2024metaformer,
author={Yu, Weihao and Si, Chenyang and Zhou, Pan and Luo, Mi and Zhou, Yichen and Feng, Jiashi and Yan, Shuicheng and Wang, Xinchao},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={MetaFormer Baselines for Vision},
year={2024},
volume={46},
number={2},
pages={896-912},
doi={10.1109/TPAMI.2023.3329173}}
}
```